First we have to create an App on the Facebook platform. We will use
this app to connect to the Facebook API. This way you can manage your
connections very good but it also has some disadvantages. Different than
in version 1 of the API you can now just get information of the friends
who are also using the app. This creates big problems as you can´t
create a friend network with all you friends anymore.
To create a new app go to https://developers.facebook.com

Click on “Apps” and choose “Add a New App“. In the next window choose “Website” and give your app a fancy name.
After clicking on “Create a New App ID“, choose a category for your app in the next window and apply the changes with “Create App ID“.
You can then click on “Skip Quick Start” to get directly to the settings of your app.

Welcome to your first own Facebook app!
Ok now we need to connect our R session with our test app and
authenticate it to our Facebook Profile for Data Mining. Rfacebook
offers a very easy function for that.
Just copy your app id and your app secret from your app settings on the Facebook developer page.
The console will then print you the message:

Copy the URL and go to the settings of your Facebook app. Click on the settings tab on the left side and then choose “+ Add Platform“.
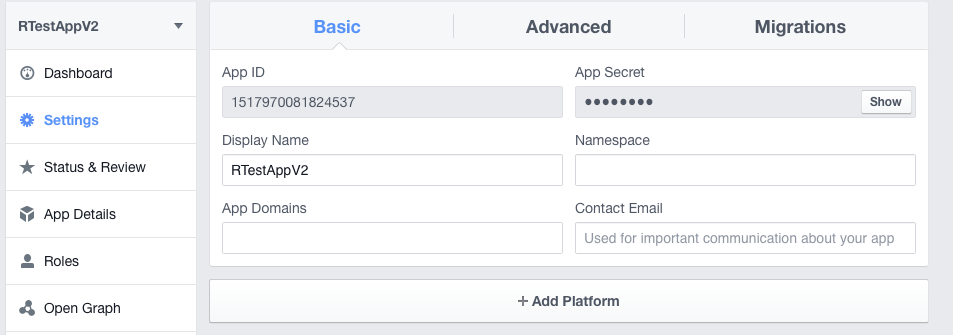
Then add the URL in the field “Site URL” and save the changes.
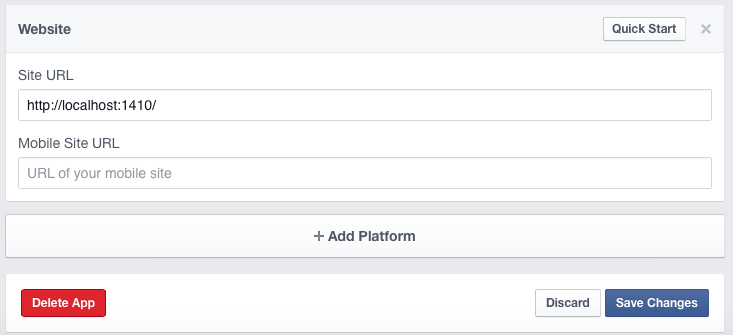
Go back to your R session and hit enter. Then a browser window should open you have to allow the app to access your Facebook account.
If everything worked the browser should show the message
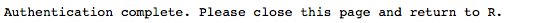
And your R console will confirm it with
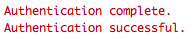
You can then save your fb_oauth object and use it for the next time.
As I mentioned before because of Facebook´s new API policies the information you can get is very limited compared to the amount you were able to download with apps using API 1.
So I will just show you now how to get your own personal information but other posts will follow with new use-cases of the new API version.
The getUsers function returns public information about one or more Facebook user. If we use “me” as the username argument, it will return our own profile info.
Now we saved our own public information in the variable „me“ and you can take a look at it.
An advantage of the new API version is that you can get more than 100 likes. You can get the things you liked with:
=====================================================================================
=========================================face-book ======================================================================================
install.packages("devtools")
library(devtools)
library(httr)
set_config(
use_proxy(url="proxy.company.co.in", port=8080, username="user@company.co.in",password="password@4321")
)
install_github("Rfacebook", "pablobarbera", subdir="Rfacebook")
require("Rfacebook")
fb_oauth <- fbOAuth(app_id="331", app_secret="f82e0ffc352f4b30c16686ccf",extended_permissions = TRUE)
save(fb_oauth, file="fb_oauth")
load("fb_oauth")
axis_page <- getPage(page="axisbank", token=fb_oauth)
icici_page <- getPage(page="icicibank", token=fb_oauth)
fb_page <- getPage(page="facebook", token=fb_oauth)
token <- "EAACEdEose0cBA"
my_friends <- getFriends(token=token, simplify=TRUE)
To create a new app go to https://developers.facebook.com
Click on “Apps” and choose “Add a New App“. In the next window choose “Website” and give your app a fancy name.
After clicking on “Create a New App ID“, choose a category for your app in the next window and apply the changes with “Create App ID“.
You can then click on “Skip Quick Start” to get directly to the settings of your app.
Welcome to your first own Facebook app!
R
First we need to install the packages devtools and Rfacebook from github as this is currently the most recent version.Just copy your app id and your app secret from your app settings on the Facebook developer page.
Copy the URL and go to the settings of your Facebook app. Click on the settings tab on the left side and then choose “+ Add Platform“.
Then add the URL in the field “Site URL” and save the changes.
Go back to your R session and hit enter. Then a browser window should open you have to allow the app to access your Facebook account.
If everything worked the browser should show the message
And your R console will confirm it with
You can then save your fb_oauth object and use it for the next time.
Analyze Facebook with R!
Now we connected everything and have access to Facebook. We will start with getting our own profile information.As I mentioned before because of Facebook´s new API policies the information you can get is very limited compared to the amount you were able to download with apps using API 1.
So I will just show you now how to get your own personal information but other posts will follow with new use-cases of the new API version.
The getUsers function returns public information about one or more Facebook user. If we use “me” as the username argument, it will return our own profile info.
An advantage of the new API version is that you can get more than 100 likes. You can get the things you liked with:
=========================================face-book ======================================================================================
install.packages("devtools")
library(devtools)
library(httr)
set_config(
use_proxy(url="proxy.company.co.in", port=8080, username="user@company.co.in",password="password@4321")
)
install_github("Rfacebook", "pablobarbera", subdir="Rfacebook")
require("Rfacebook")
fb_oauth <- fbOAuth(app_id="331", app_secret="f82e0ffc352f4b30c16686ccf",extended_permissions = TRUE)
save(fb_oauth, file="fb_oauth")
load("fb_oauth")
axis_page <- getPage(page="axisbank", token=fb_oauth)
icici_page <- getPage(page="icicibank", token=fb_oauth)
fb_page <- getPage(page="facebook", token=fb_oauth)
token <- "EAACEdEose0cBA"
my_friends <- getFriends(token=token, simplify=TRUE)